Er gaat serieus geld naar AI visibility tools. SparkToro noemt een schatting van $100M+ per jaar aan spend in deze markt. Klinkt logisch: je wilt anno 2026 weten of je merk genoemd wordt in ChatGPT, Claude of Google AI. Alleen… nieuw onderzoek prikt door de belofte heen. Als dezelfde vraag bijna nooit hetzelfde antwoord oplevert, wat ben je dan precies aan het meten?
In dit blog leer je:
- Waarom “positie 1 in ChatGPT” geen stabiele KPI is
- Wat de 1-op-100 en 1-op-1.000 bevindingen betekenen voor AI-rank tracking
- Waarom AI-antwoorden wisselen, zelfs bij identieke prompts
- Hoe je AI-zichtbaarheid wel zinvol meet (share of voice)
- Waarom aanwezigheid in de ‘consideration set’ belangrijker is dan volgorde
De illusie van vaste posities in AI
SparkToro lieten 600 vrijwilligers 12 identieke prompts draaien in ChatGPT, Claude en Google AI. In totaal leverde dat 2.961 runs op. Daarna zijn de antwoorden omgezet naar “merkenlijsten” zodat je appels met appels vergelijkt.
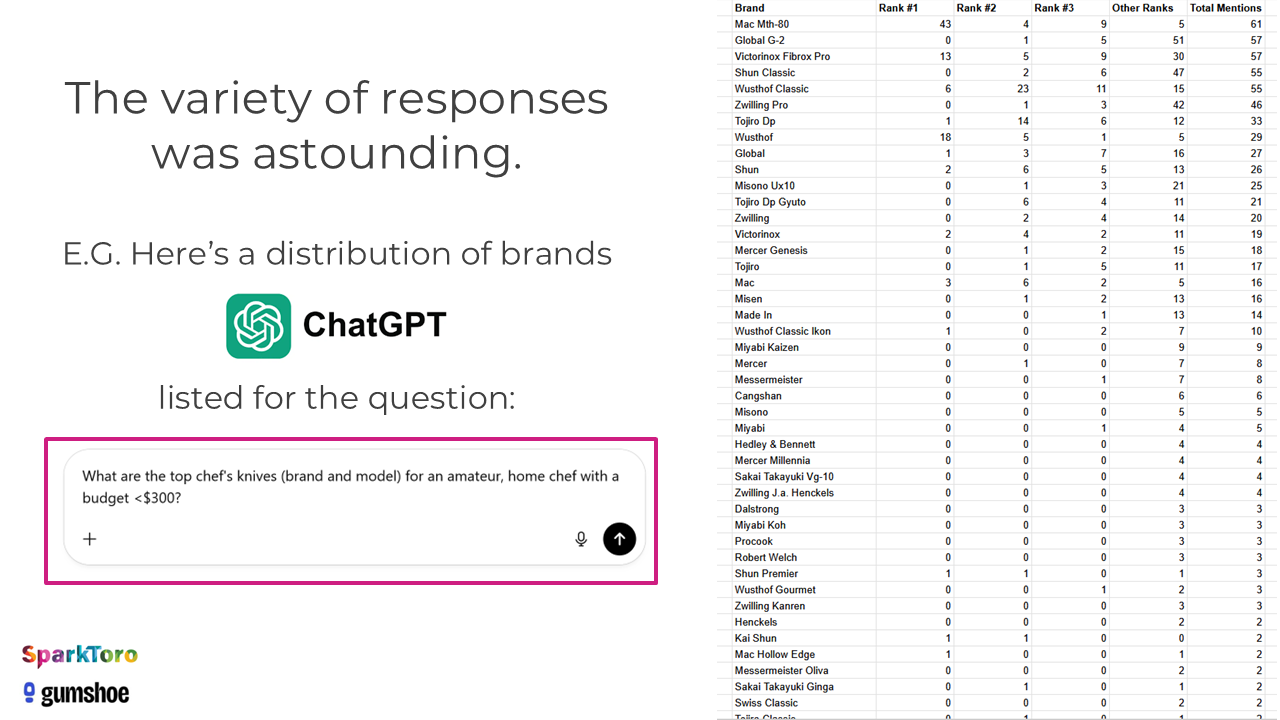
Belangrijkste bevindingen
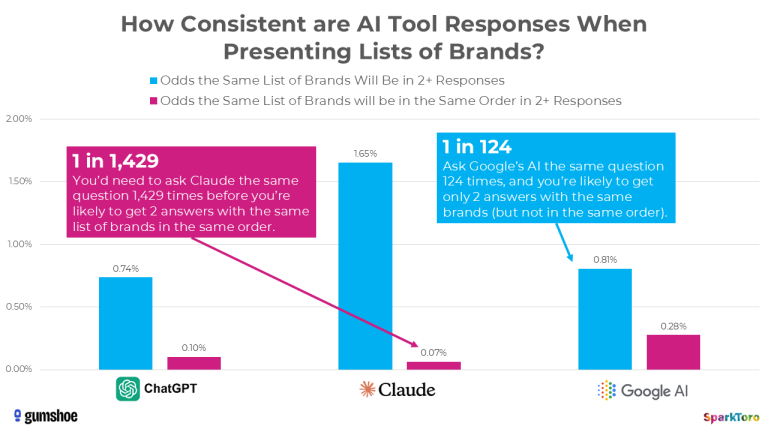
- De kans dat ChatGPT of Google AI exact dezelfde lijst met merken genereert bij een herhaalde, identieke prompt, is kleiner dan 1%;
- De kans dat deze merken in dezelfde volgorde worden gepresenteerd, is nog kleiner: minder dan 0,1% (oftewel minder dan 1 op de 1.000 keer);
- Claude bleek iets consistenter dan de rest, ongeveer 2% herhaalbaarheid maar nog steeds volstrekt onvoldoende voor betrouwbare rank tracking;
- Het onderzoek concludeert het claimen van een specifieke AI-ranking positie, bijvoorbeeld: “U staat op plek 1 in ChatGPT” niet klopt.
Waarom wisselt het zo?
Dit onderzoek laat vooral een ding zien: variatie in de resultaten is geen uitzondering maar de standaard. Dat komt grofweg door 3 oorzaken.
- Versie van het model
AI-systemen worden continu aangepast. Soms zit je op een andere modelversie, soms op een andere configuratie. Dat kan al genoeg zijn voor andere merken in het antwoord. - Context en interpretatie
Ook al is je prompt identiek maar een model “leest” het niet zoals een zoekmachine. Het interpreteert de vraag en kiest telkens een net andere route naar het antwoord. - Variatie zit ingebouwd in hoe Large Language Models (LLM) output genereren
Het antwoord vanuit een AI-tool is een steeds opnieuw gegenereerde tekst. En bij genereren hoort variatie, dat zit ingebouwd bij AI-tools zoals ChatGPT, Claude en Google AI.
Wat betekent dit voor jou?
Als je wilt voorkomen dat je elke week een nieuw “ranking-paniekmoment” creëert, moet je anders rapporteren. Minder naar “plekjes” kijken, meer naar kans en herhaling.
- Rapporteer in percentages, niet in posities (Share of Voice)
Een AI-antwoord is geen Google-ranking. Dus stop met “we staan op plek 3”.
Rapporteer liever: “we worden genoemd in 14% van de antwoorden binnen dit onderwerp.” Dat is eerlijker en je kunt er iets mee. - Focus op aanwezigheid in de “Consideration Set”
De volgorde van merken in AI-lijstjes is bijna nooit hetzelfde (minder dan 0,1% kans op dezelfde volgorde). Maar het onderzoek laat ook iets anders zien. Topmerken zoals Bose of Sony komen wel vaak terug, in ongeveer 55–77% van de antwoorden. Jouw doel is dus niet een specifieke rang, maar structureel aanwezig zijn in die vaste groep aanbevelingen.
Als je dit onderzoek 1 ding leert, dan is het dit: stop met doen alsof AI een ranglijst is. ‘Positie 1 in ChatGPT’ klinkt lekker in een rapport, maar het zegt in de praktijk nauwelijks iets over je zichtbaarheid.
Meer weten over AI-Search?
Wil je weten hoe jouw content scoort in AI-Search? Of heb je hulp nodig bij het optimaliseren? Een online marketing bureau zoals Sageon helpt je graag verder. Neem contact op voor een vrijblijvend gesprek.




